Unity中的profiler用于CPU的性能优化时非常方便,但是用于GPU性能优化时无法提供足够多的信息,于是我们决定常识使用Nvidia Nsight Graphics进行GPU Profiling。
安装版本
首先,安装Nsight Graphics 2021.2.0,注意 2021.2.0 以上版本才刚刚支持GPU Trace Analysis,可以为分析性能瓶颈提供一些参考。
GPU Trace Analysis具体使用方式可以看GTC2021上最新的一个报告:https://gtc21.event.nvidia.com/media/t/1_idigifru/204678193(与本文关系不大)
由于本文没有重度使用GPU Trace Analysis,所以Nsight Graphics 2021.2.0以下版本应该也可以同样使用。
与Unity连接
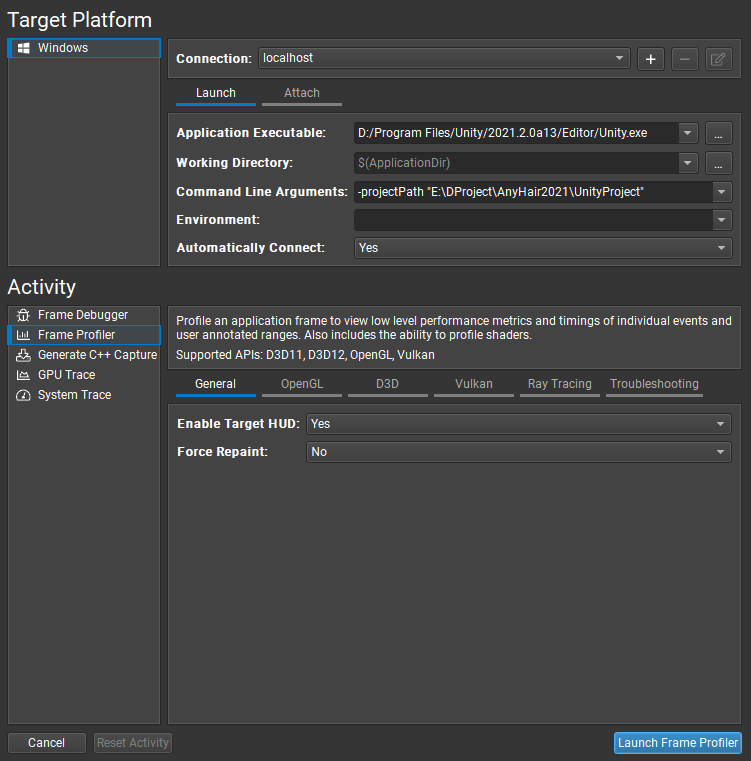
如图填写即可,分别填写Unity安装位置和项目根目录,可以启动Frame Profiler或者GPU Trace。
参考用户手册:https://docs.nvidia.com/nsight-graphics/UserGuide/
使用GPU Trace和Range Profiler进行性能分析
Nsight Graphics中涉及到大量GPU相关的参数,以及一些Profiling时的常用缩写,需要对于GPU的运行原理有一定了解。

这里推荐几篇非常好的文章:
GPU运行管线:https://developer.nvidia.com/content/life-triangle-nvidias-logical-pipeline
通过Range Profiler进行性能分析:https://developer.nvidia.com/blog/the-peak-performance-analysis-method-for-optimizing-any-gpu-workload/
通过GPU Trace的advanced mode进行性能分析:https://developer.nvidia.com/blog/optimizing-vk-vkr-and-dx12-dxr-applications-using-nsight-graphics-gpu-trace-advanced-mode-metrics/
读过以上三篇文章,基本上可以根据GPU的运行参数,推测出Shader送入GPU后主要的时间消耗,做出一些模糊的判断,但是无法知道是哪一个语句造成的。
使用Shader Profiler进行逐句分析
由于在GPU Trace和Range Profiler里面还是很难精确定位Shader导致的性能问题,于是我们找到了另外的方式实现定位,那就是Shader Profiler。
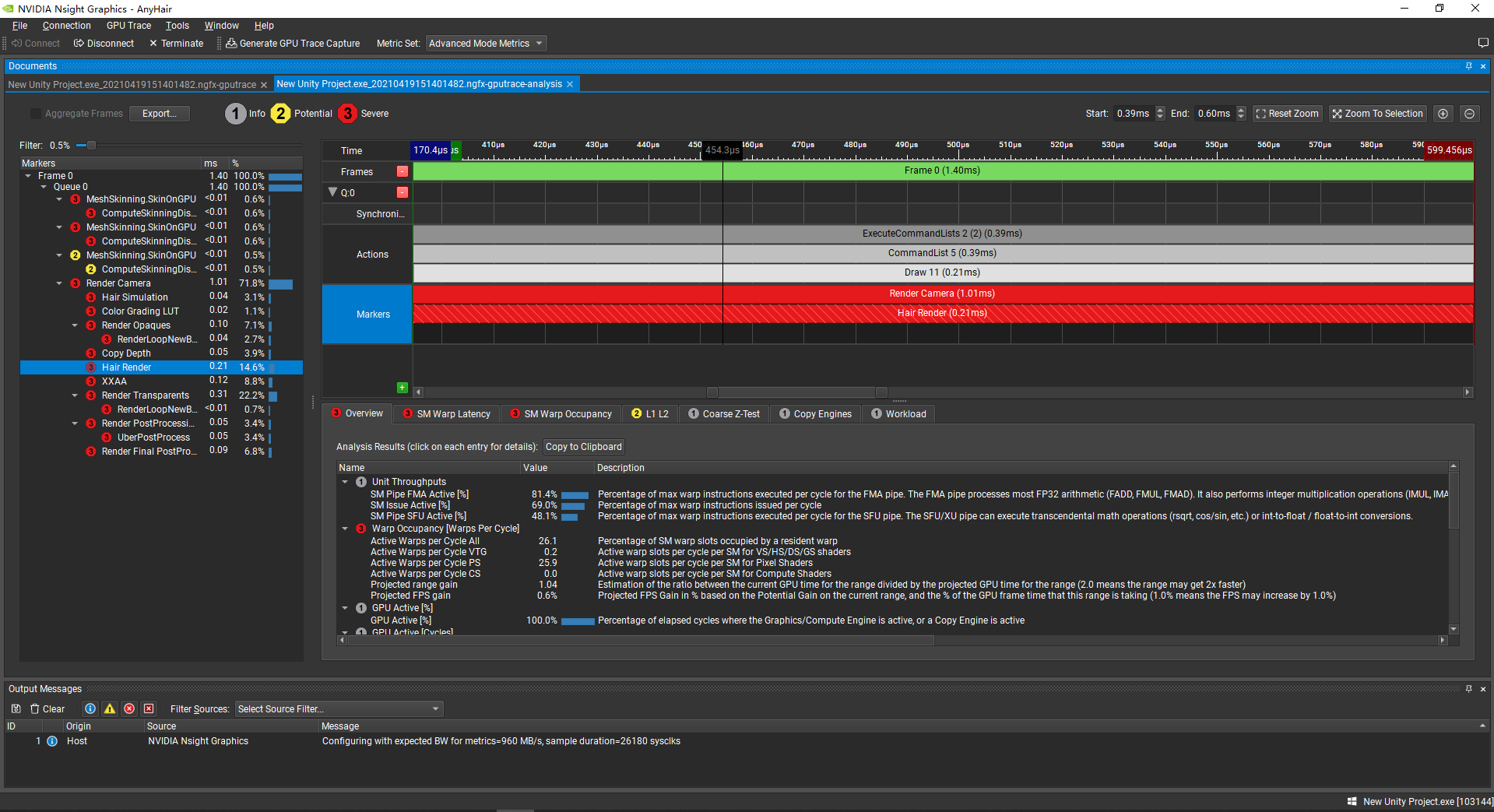
我们在Range Profiler里找到需要分析的阶段,然后右键打开Shader Profiler。但是当打开Shader Profiler后,可能会出现Hot spot information unavailable的情况。我们使用Shader Profiler来进行性能瓶颈的定位,其实就是需要Hot spots一栏的信息,这下怎么办呢?
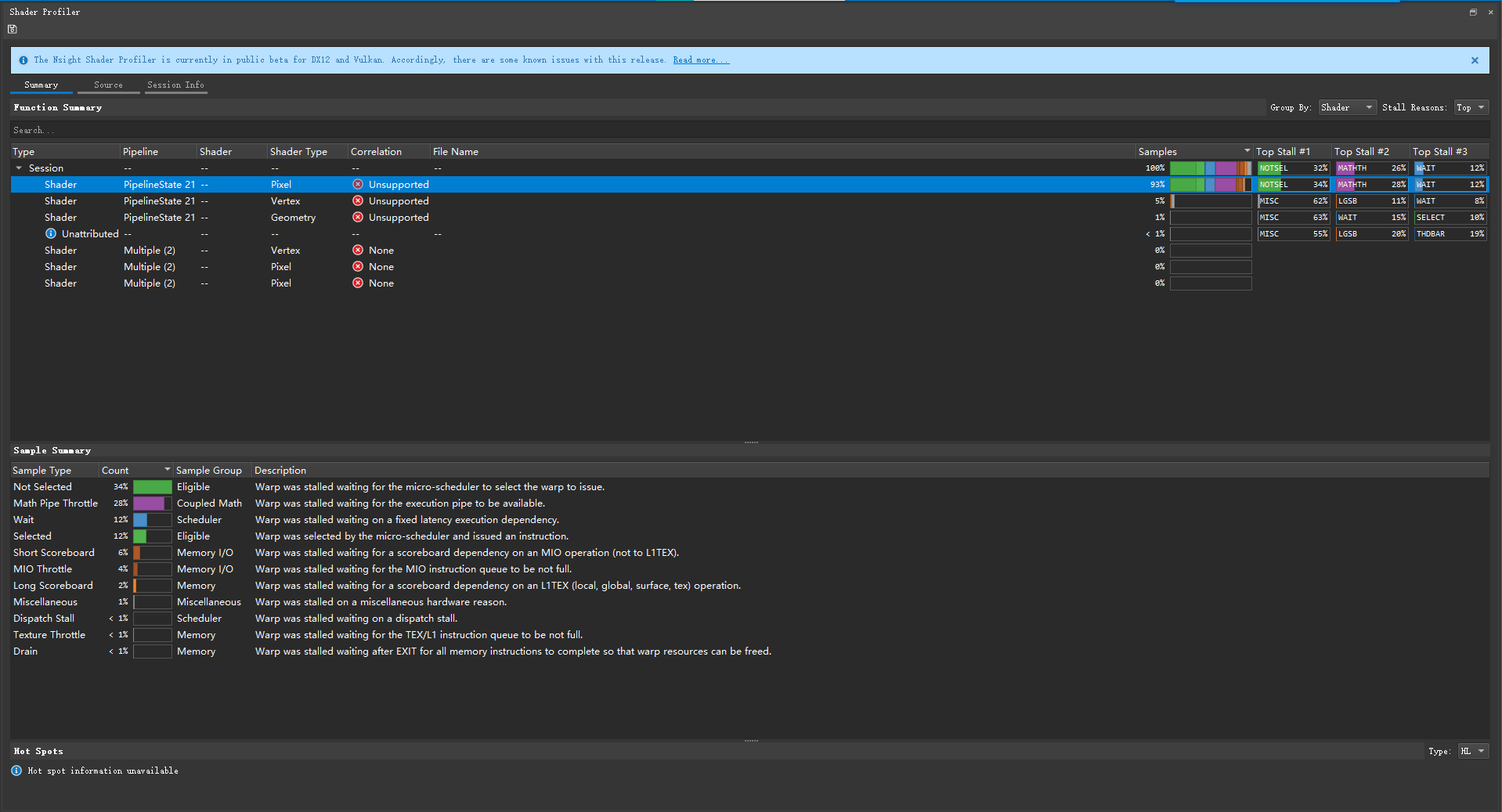
其实这是因为目前Nsight Graphics仅支持编译后为DXIL中间码的Hot spots显示,而Unity在2021.2版本才刚刚支持将shader编译器从DXC切换到FXC,将编译中间码从DXBC转到DXIL。所以想要定位问题,必须将项目升级至Unity 2021.2,同时将图形API切换至DX12,记得备份一份原项目文件以防升级造成的改动。
记得给要分析的Shader文件中加入 #pragma use_dxc和#pragma enable_d3d11_debug_symbols
参考文档:
https://forum.unity.com/threads/unity-is-adding-a-new-dxc-hlsl-compiler-backend-option.1086272/
https://docs.google.com/document/d/1yHARKE5NwOGmWKZY2z3EPwSz5V_ZxTDT8RnRl521iyE/edit
分析DXIL中间码
升级后会发现Hot spots栏里终于出现了内容,但是并不是我们想要的Shader源码,而是DXIL文件,这是因为找不到Unity编译Shader时的PDB符号文件,所以无法从DXIL转译回源码。这里我和Unity的技术支持沟通过了,Unity目前使用DXC编译Shader时直接使用的是Release Mode,所以并没有生成PDB文件,也不确定未来会不会支持Debug Mode编译Shader。
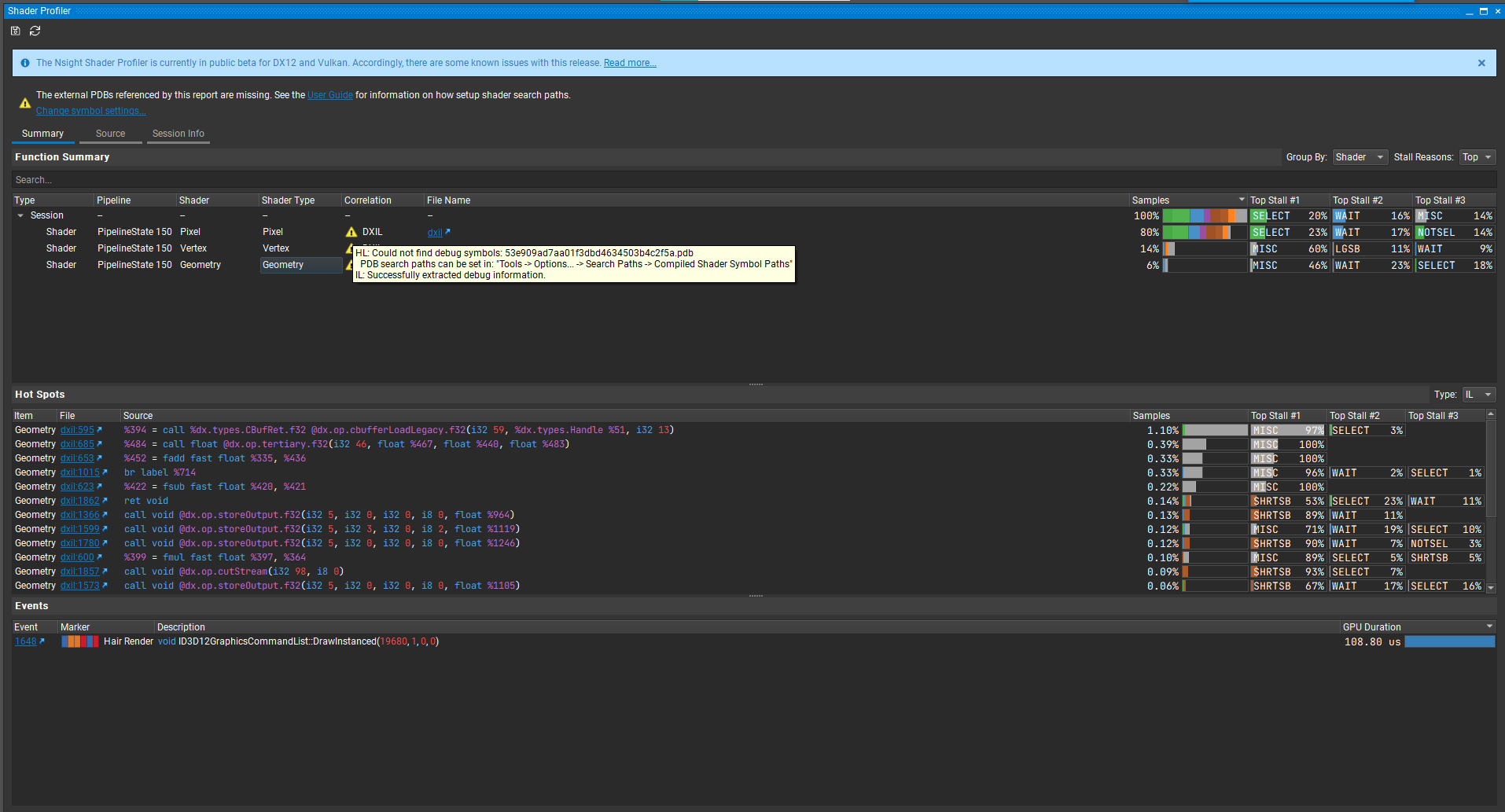
既然如此,我们目前只能从DXIL文件来分析瓶颈语句了。
DXIL的语法是LLVM汇编语言的一个子集,通过以下文档大致了解一下之后就可以通过DXIL反推源码了,这个过程有种做数独的推理趣味,还是蛮有意思的。
https://github.com/microsoft/DirectXShaderCompiler/blob/master/docs/DXIL.rst
https://llvm.org/docs/LangRef.html
将Top Stall前几名的语句反推回源码,然后分析一下上下文,再结合之前Range Profiler和GPU Trace的结果,基本上就可以确定Shader的性能瓶颈了。
案例分享
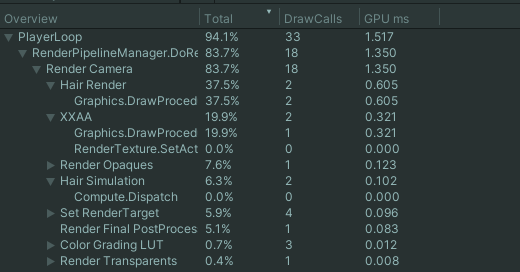
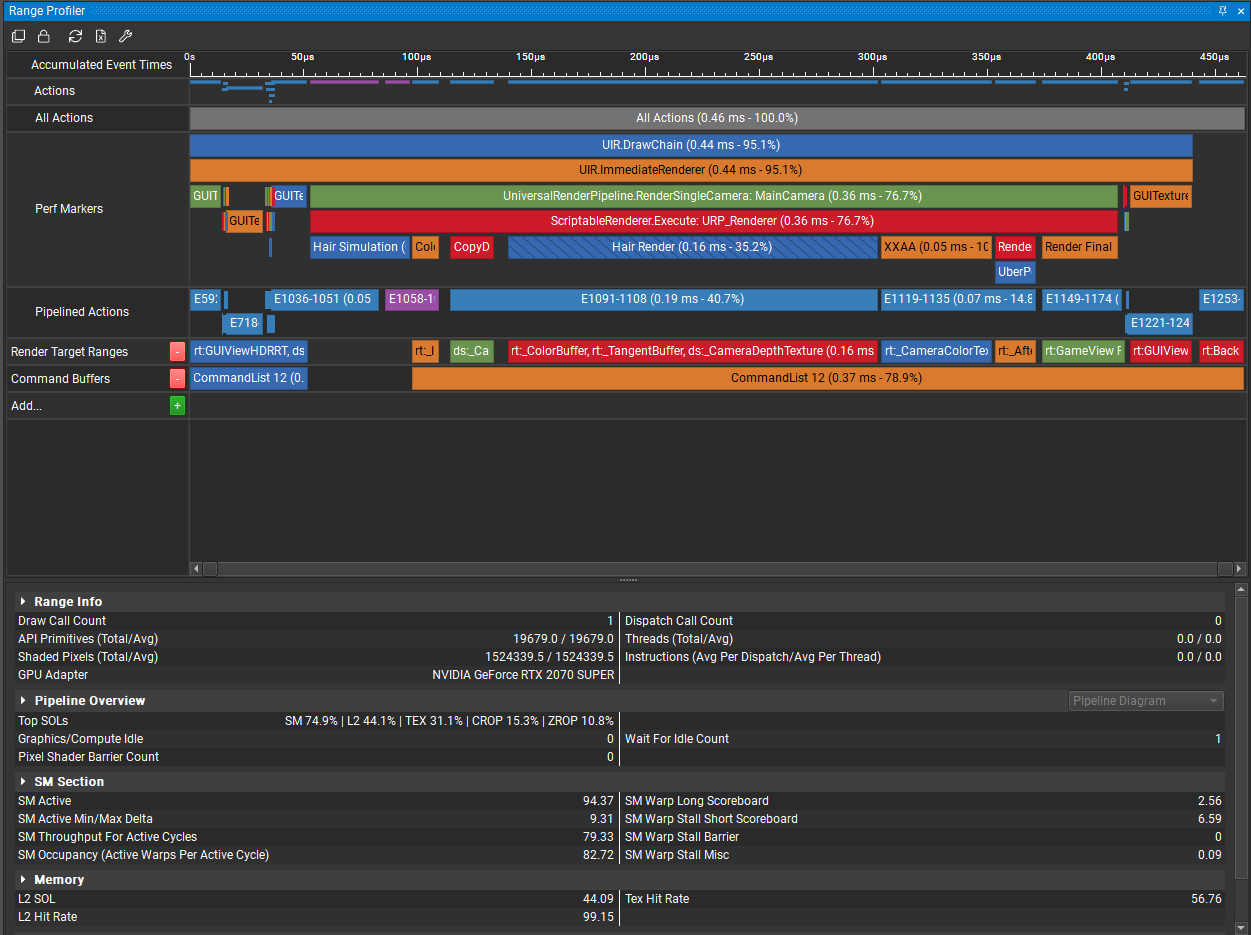
以Anyhair URP为例,在优化Hair Render阶段时,我使用Range Profiler测出如下结果:
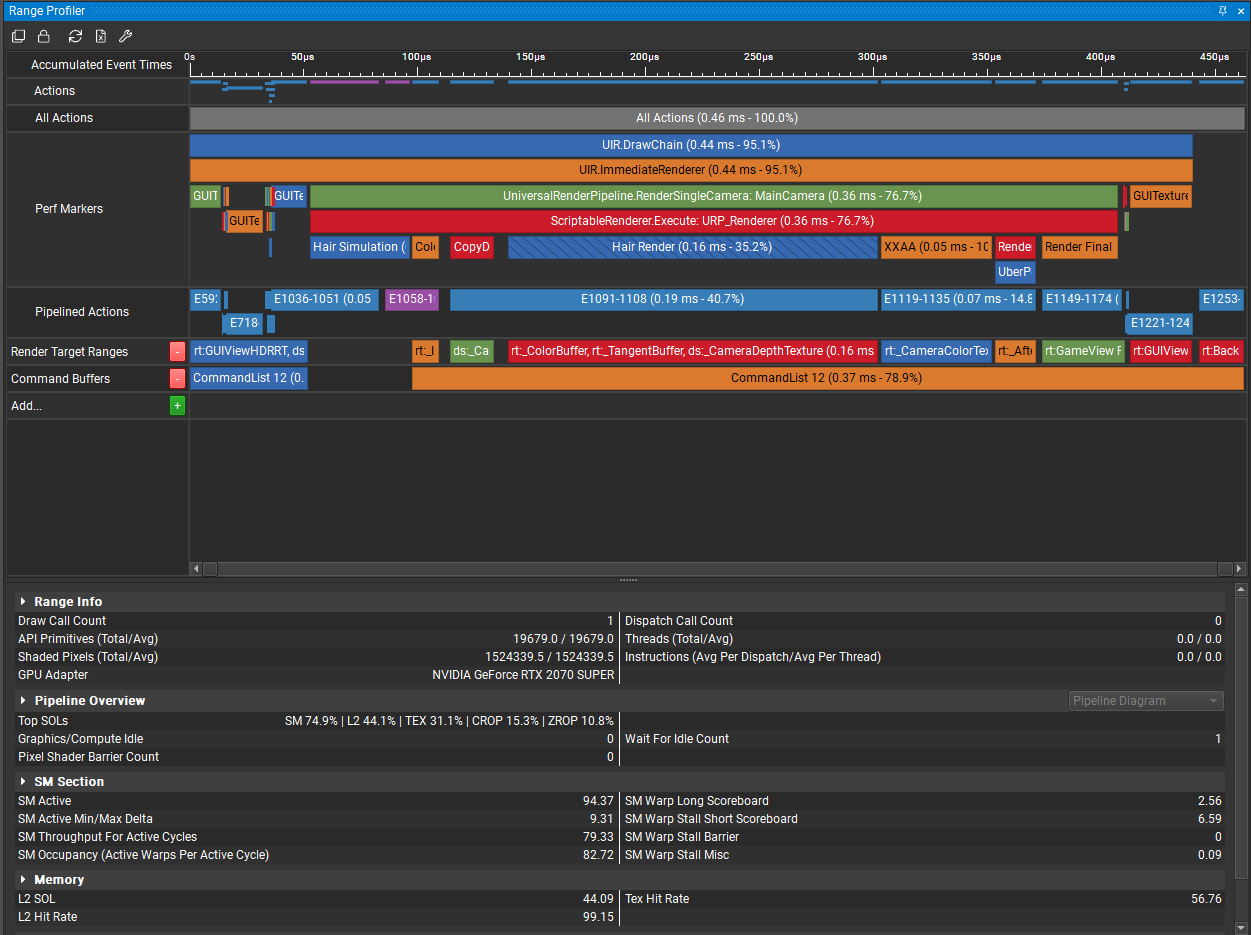
在这里可以看出Top SOLs主要是SM 74.9%,介于60%-80%之间,看不出什么问题,然后SM Active为94.37%,Graphic/Compute Idle为0,可以看出SM利用率很高,并没有被闲置的迹象。
L2 Hit Rate极高,说明L2缓存利用率没有问题;但是Tex Hit Rate略微有点低,但是看不出问题在哪。
展开Pipeline Overview,可以看到主要性能消耗在Pixel Shader上。同时通过观察Texture、L2、VRAM的Throughput,可以发现VRAM的Throughput极低,而L2的Troughput较高,这说明SM频繁从L2读取而很少从VRAM读取数据,与之前分析的L2命中率极高而L1命中率略低相吻合。

之后打开Shader Profiler进行进一步分析:
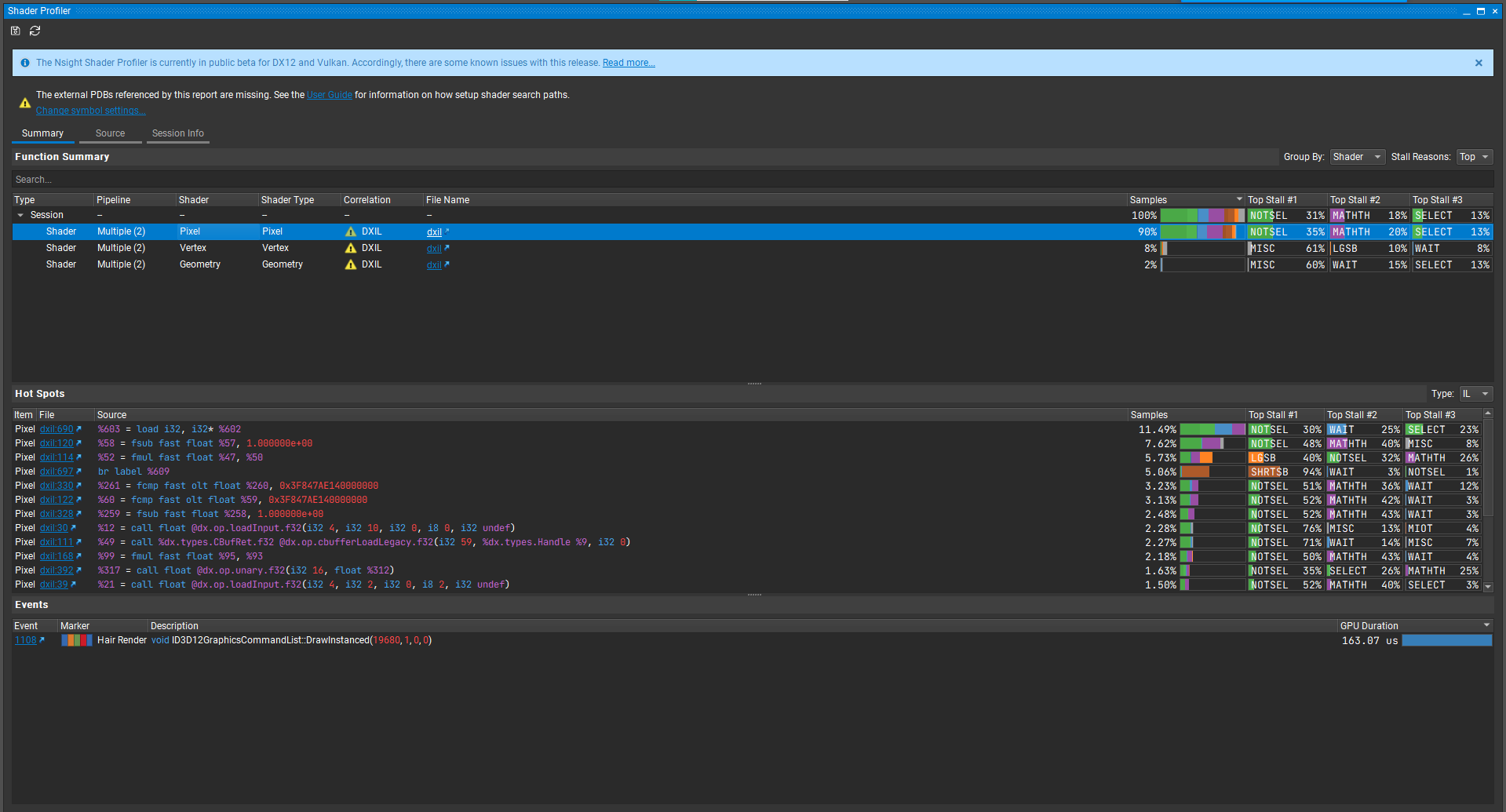
可以发现排最前的几个Top Stall的原因是Not Selected,这代表着SM中有一些Warp有时处于闲置状态。
通过反推Hot Spots中的DXIL语句,我发现Stall主要集中在运行时的if & else语句处,于是推测由于GPU的并行机制,同一Warp的不同Thread无法在同时运行不同分支的语句,出现了下图情况:
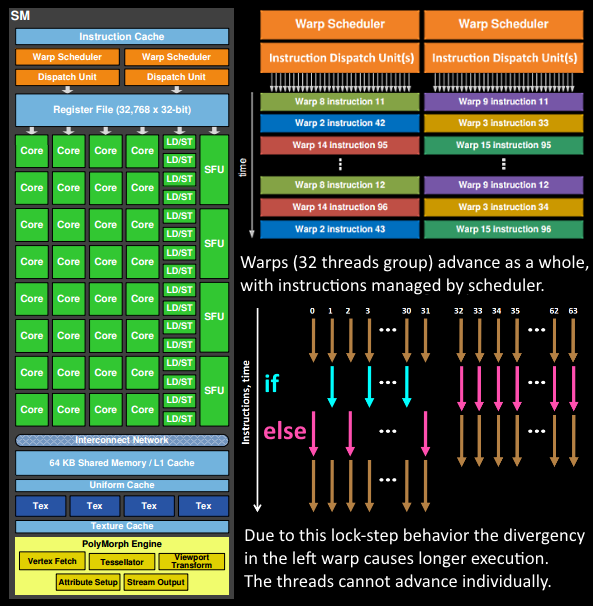
于是我将一些可以放在预编译阶段的分支语句改为了#ifdef & #else的形式,重新进行测试:
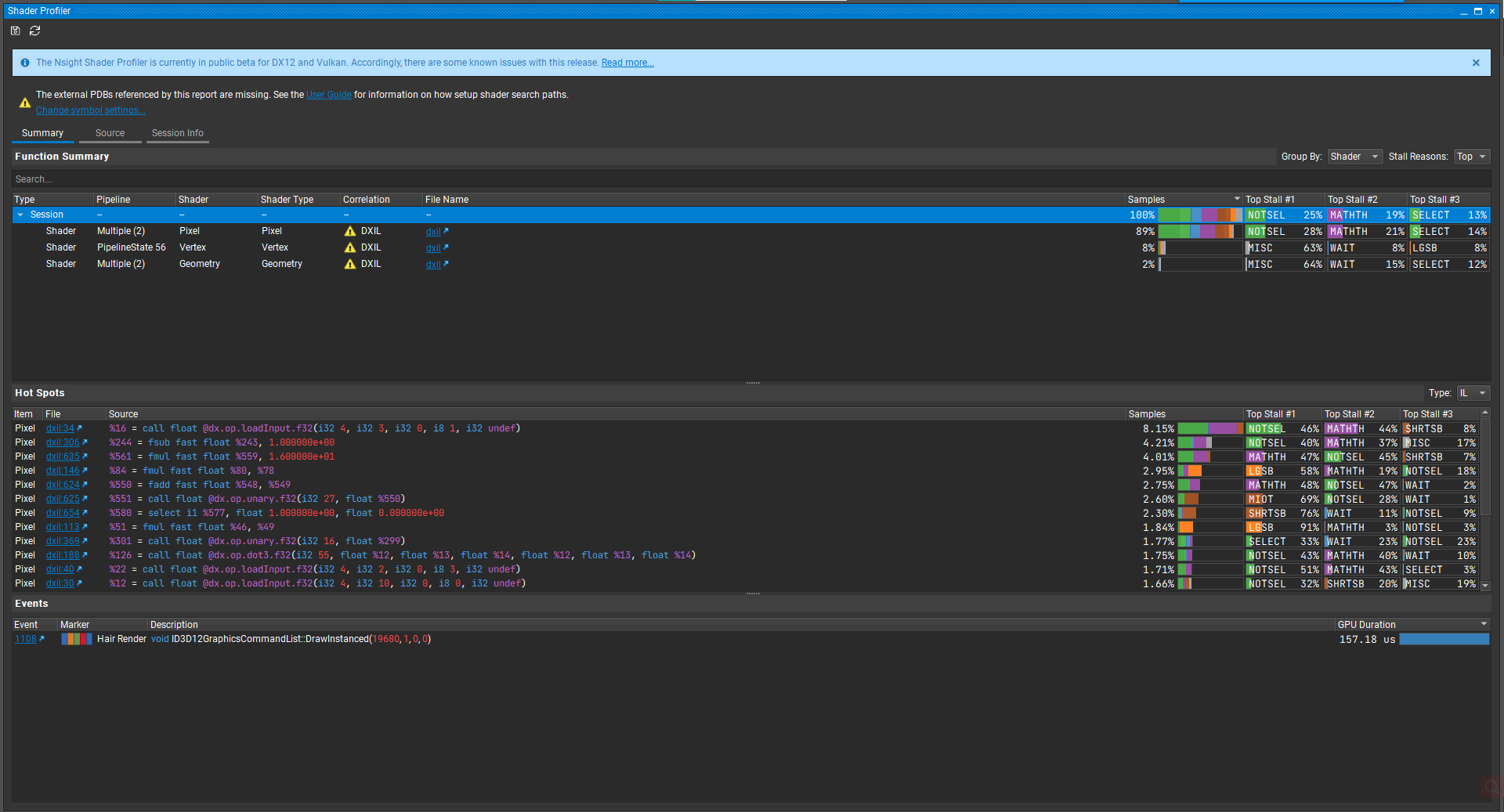
可以看到百分比略有降低,但是效果并不显著,而且Top Stall依然是Not Selected,这是什么原因呢?
经过一番推测,这可能是代码中隐含的最大分支,clip()语句引发的问题。我们猜测被discard的大量像素并非彻底不再占用资源,而是占用了一些Warp等待其他非discard的像素运行完成。
于是我先注释掉代码中的clip(),发现果然Not Selected的百分比大幅下降了:
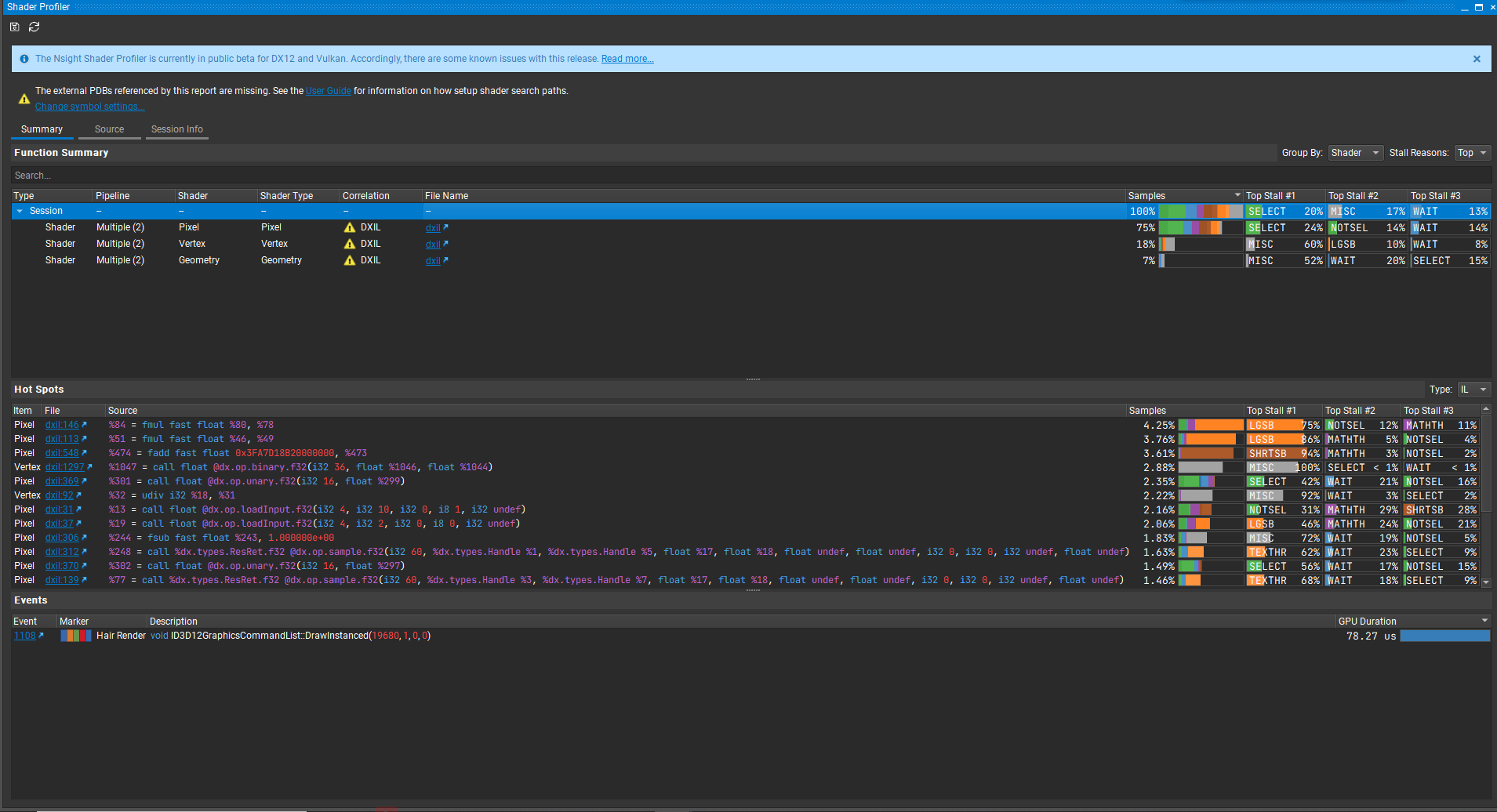
那么,为了解决这一问题,我们决定采用在之前加一个Depth Prepass的方案,在Depth Prepass中discard不需要的像素,然后在颜色渲染Pass中设置ZTest为Equal,触发Early-Z,仅绘制Depth Prepass中保留的像素,这样就避免了在繁重的颜色渲染Pass中进行discard造成分支。
但是这样做也有一个潜在的缺点,那就是VS和GS会多运行一次,可能浪费的时间比PS中节省的时间还多。不过我们在Shader Profiler里可以看到VS和GS的占比总和才不过10%,PS才是主要的时间消耗者,所以预测不会出现这种情况。
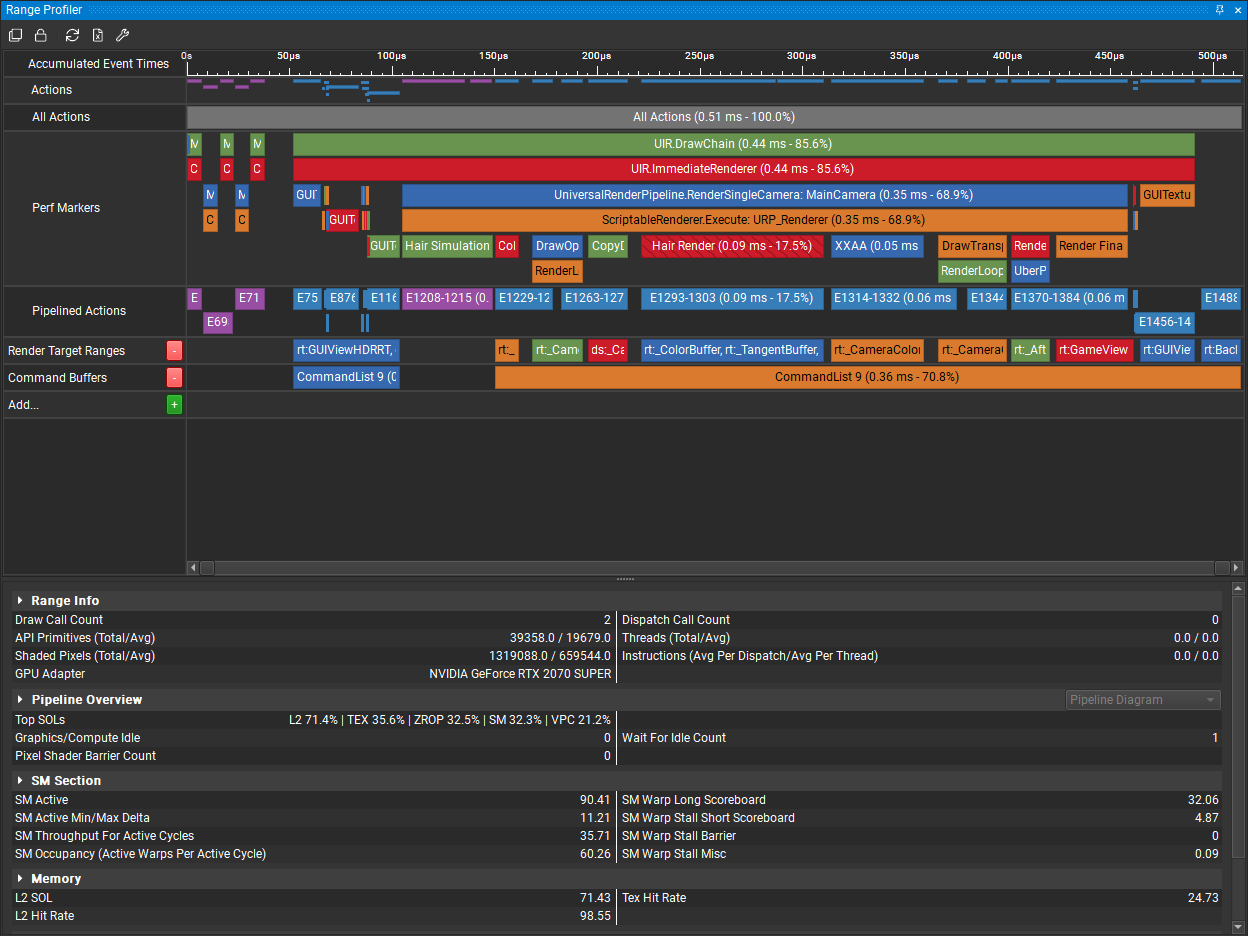
经过一番改造,发现总时长如愿大幅缩减了,从0.16ms缩减到0.09ms!
但是让我们看看还有什么可以改造的点,Holy Shit,Tex Hit Rate这项数据也太差了吧,命中率才24.73%,打开Shader Profiler看看发生了什么:
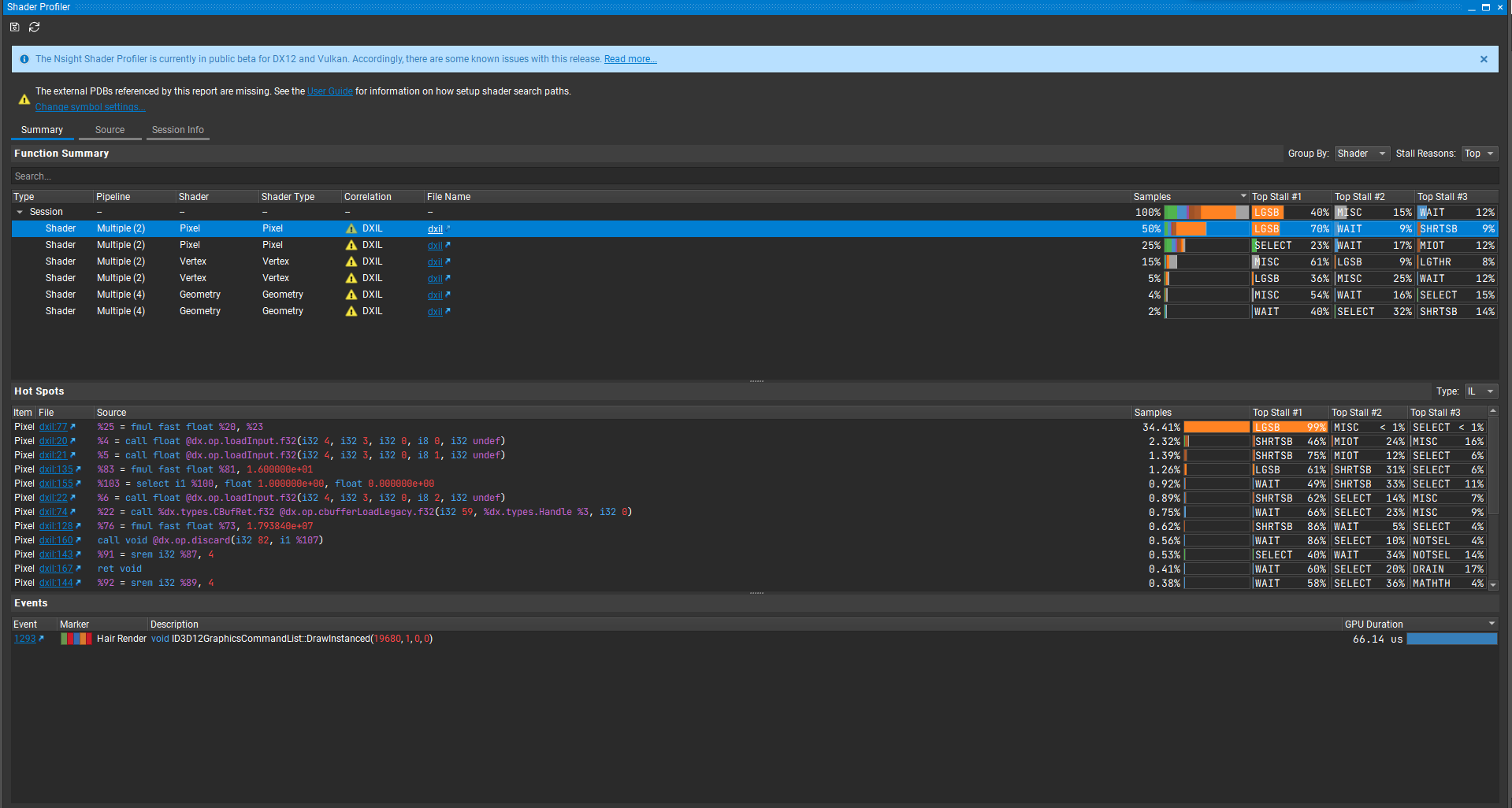
可以看到Tops Stall Reason是Long Scoreboard,这说明是数据读取的问题,正好与低Tex Hit Rate相对应。
解码后推测是Depth Prepass中Sample一个Texture 时,命中率过低。经过一番排查,最终发现是由于这个长方形纹理导入Unity时没有自动勾选Generate Mip Maps选项导致。
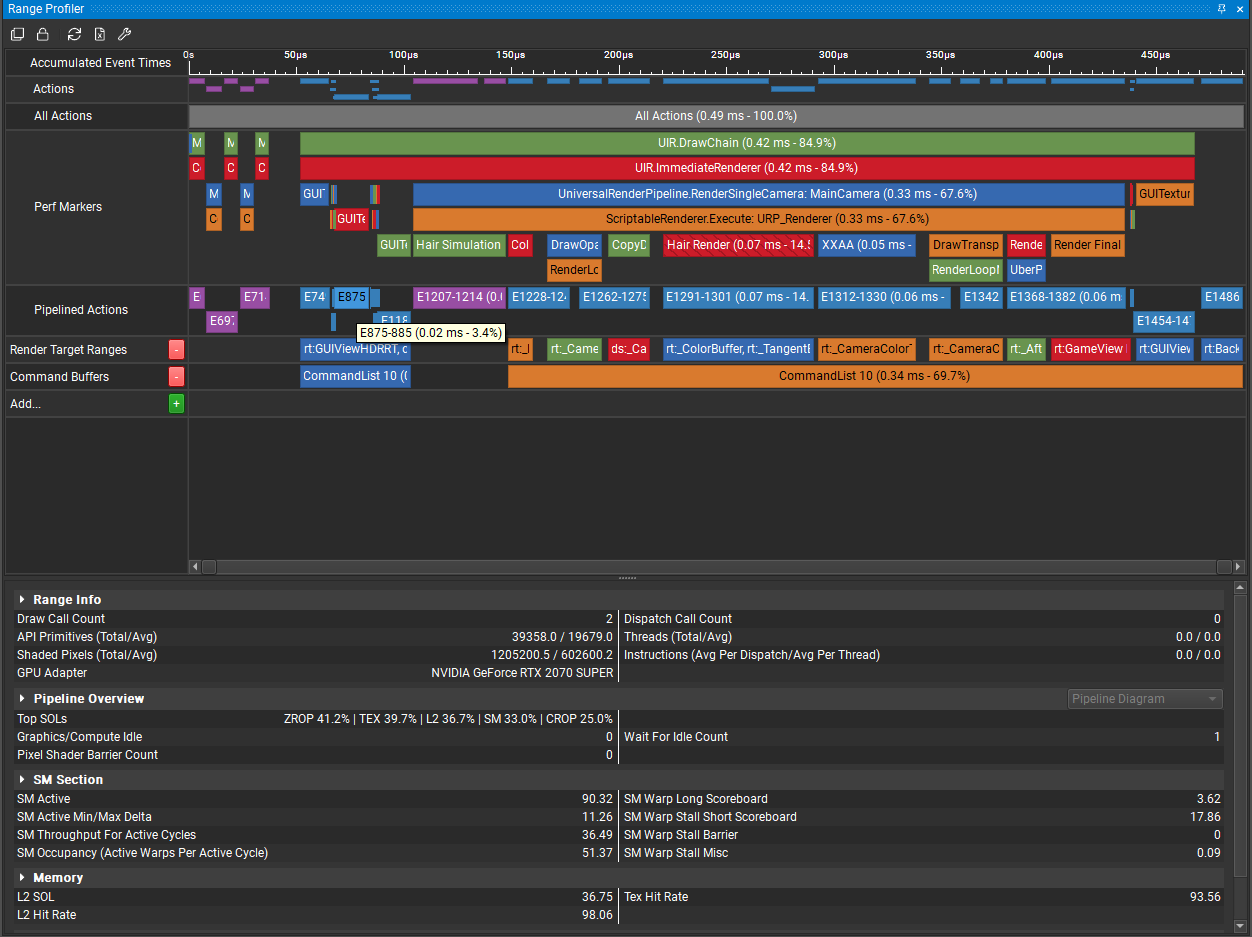
勾选Generate Mip Maps后,Tex Hit Rate直接上升到了93.56%,总时间也缩短到了0.07ms
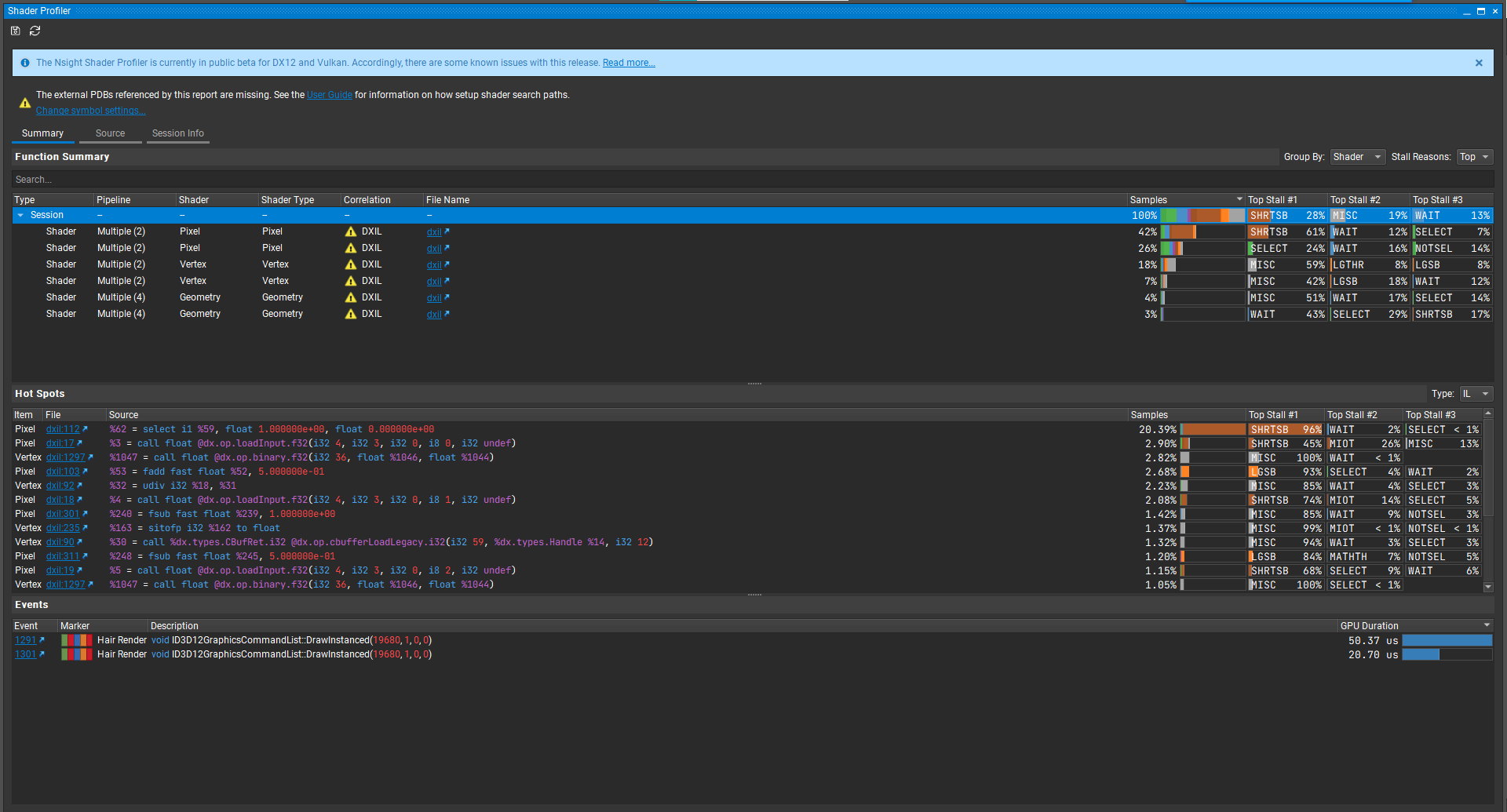
点开Shader Profiler,发现Top Stall不再是Long Scoreboard了。
所以最终的优化结果就是将Hair Render阶段从0.16ms优化到了0.07ms,虽然这个数字很小,但是这是在RTX 2070 Super上的测试结果,相应在移动端节省的时间应该是比较多的。
参考文献与扩展阅读汇总
Nsight:
https://docs.nvidia.com/drive/drive_os_5.1.12.0L/nsight-graphics/user-interface-reference/index.html
https://docs.nvidia.com/nsight-graphics/UserGuide/
https://docs.nvidia.com/cupti/Cupti/r_main.html#r_host_metrics_api
https://developer.nvidia.com/content/life-triangle-nvidias-logical-pipeline
https://docs.google.com/document/d/1yHARKE5NwOGmWKZY2z3EPwSz5V_ZxTDT8RnRl521iyE/edit#
https://docs.nvidia.com/nsight-graphics/UserGuide/index.html#global_options_search_paths
PIX:
https://devblogs.microsoft.com/pix/gpu-captures/
https://devblogs.microsoft.com/pix/using-automatic-shader-pdb-resolution-in-pix/
DXIL:
https://github.com/microsoft/DirectXShaderCompiler/blob/master/docs/DXIL.rst
https://llvm.org/docs/LangRef.html